-
탐욕적 기법
탐욕적 알고리즘
에서 시작, 탐욕적인 기준에 따라 아이템을 차례로 추가하여 문제의 해답이 될 까지 계속하는 기법
단계
- 선택 과정
- 기준에 따라 현제 상태(Locally)에 최적의 선택
- 적정성 검정
- 해답 점검
-> 동적 보다 쉽다. 해답이 항상 최적해를 보장하지 않는다. 그래서 증명이 필요하다. 반드시
연속 배낭문제
- 각 아이템을 잘라서 배낭에 넣을 수 있다.
- 용량을 초과하지않고 아이템 가치의 합이 최대가 되도록 담기
- 정렬로도 풀 수 있다.
탐욕적 알고리즘과 우선순위 큐
탐욕적 알고리즘 구현은 우선 큐를 동반한다.
큐 (Queue)
Queue는 리스트라고 하는 선형 구조
- 만족하는 조건
- FIFO(선입선출)
- 들어온것 : 입력
- 나가는것 : 삭제
Queue에서 중요한 것
- 입력 순서가 중요하다.
우선순위 큐 (Priority Queue)
우선 순위를 보고,삭제 순서를 정한다.
우선순위 큐 구현
- 힙(Heap)으로 구현한 우선순위 큐가 가장 빠르다
- 미리 정렬한 후 순차적으로 선택 O(nlg m)
- 단계마다 최대(or 최소)를 검색 O(n*n)
스케줄링 문제
시스템 내부 시간의 합을 최소로 하는 스케줄링
- 시스템 내부 시간의 합을 최소로 하는 스케줄링
- 시스템 내부 시간 : 기다리는 시간 + 작업시간
- p1, p2 가 있으면,
- p1의(기다린 시간 + 작업시간) + p2의(기다린 시간 + 작업시간)게 계산한다.
- p1과 p2는 독립된 개체로 서로 느끼는 시간이 다르다.
- p1 = 9, p2 = 12 라면, 이 둘이 시스템에 머무른 시간은 21이다.
- p1, p2 가 있으면,
- 탐욕적 전략 : 작업시간이 짧은 작업부터 한다. 증명이 필요하다.
Chapter 5: CPU Scheduling
Basic Concepts(개념) cpu scheduling: 순서를 정하는 것이다.(multiprograming) 하는 이유 cpu의 활용을 maximum으로 하기위해 -> 이러면 cpu가 놀지 않고 일한다. 그러면 process들이 일을 빨리할 수 있다. Bur..
cmscms419.tistory.com
마감 시간이 있는 스케줄링
직업별 마감 시간(deadline)과 이익을 갖는 n개의 작업
- 작업은 단위시간(1)걸린다.
- 작업이 마감 시간 전이나 마감 시간이 시작된다면, 그 이익을 얻게 된다.
예)


- 마감 시간 0은 말 그대로 시간이 없다는 것이다.
- '작업 1'은 마감 시간 1 ~ 3 사이에 작업을 할 수 있다. 마감 시간 2 초과하면 '작업 1'을 못한다.
- 이 스케줄링에서는 "작업 2 -> 작업 1"을 하면 제일 큰 이익을 얻을 수 있다.
- 왜냐하면, "작업 2"의 마감 시간이 1임으로 1에서 시작하면, 이익을 얻고 시간 2가 된다. "작업 1"은 마감시간이 3임으로, 시간이 3 초과가 되지 않으면 작업을 할 수 있다.

혹은

이렇게도 된다.
탐욕적 전략 : 이익이 큰 자업부터 하나씩 추가하여 적정성 체크 한다.
-> 이익이 큰 것부터 차례로 정렬이 되어있다고 가정한 것이다.
탐욕적 알고리즘의 시간복잡도
전체시간 = 정렬시간 + 추가시간 + 적정성 체크

= O(nlgn) + O(n*n) + O(n*n)
= O(n*n)
허프만 코드
최적이진코드(optimal binary code) 문제
- 데이터 압축(data compression) 문제
- 최소 중복 코딩
코드워드(codeword) : 각 문자를 표현하는 고유한 이진 문자열
전치 코드(prefix code) : 한 문자의 코드워드가 다른 문자의 코드워드의 앞부분과 일치하지 않는 코드
- 파일을 파스(parse) 할 때 현재 파스하고 있는 지점의 앞부분을 미리 볼 필요학 없다
- 전치 코드는 잎이 코드문자로 구성된 이진트리로 표현 가능
-> 최적 이진 코드 문제 : 파일에 있는 텍스처를 최소로 하는 이진트리를 구하는 문제이다.
허프만 코드(Huffman code)
최적 코드에 해당하는 이진트리를 구축하여 최적이진문자코드를 만드는 탐욕적 알고리즘
우선순위 대기열을 이용한다.

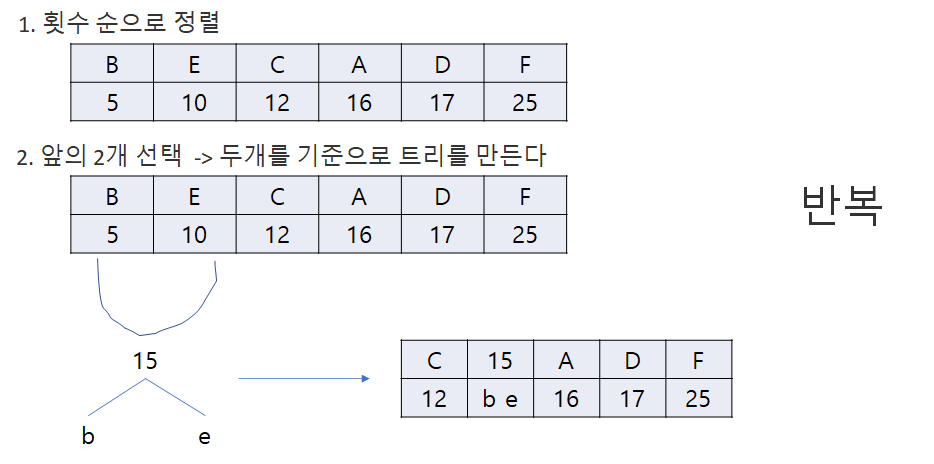
결과

왼쪽 선은 0, 오른쪽 선은 1
-> 위의 허프만 코드처럼 나온다
- 선택 과정