-
Chapter 5: CPU Schedulingos 2020. 9. 28. 12:01
Basic Concepts(개념)
cpu scheduling: 순서를 정하는 것이다.(multiprograming)
하는 이유
cpu의 활용을 maximum으로 하기위해
-> 이러면 cpu가 놀지 않고 일한다. 그러면 process들이 일을 빨리할 수 있다.
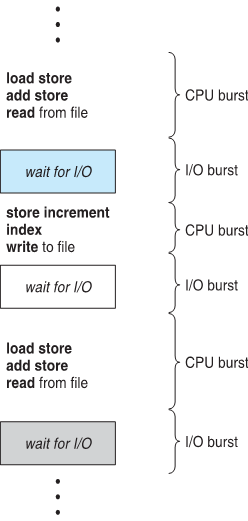
Burst: 시간
Cpu burst: cpu를 사용하는 시간
I/O burst: I/O를 사용하는 시간

Histogram of CPU-burst Times CPU를 사용하는 시간 0~8에서 process를 쓰고, 그 뒤는 거이 쓰지 않는다.
-> process는 CPU를 사용하는 시간이 아주 짧다.
CPU Scheduler
CPU의 scheduling이 필요로 할 때
- running -> waiting
- running -> ready state
- waiting -> ready
- terminates 때
scheduling하는 방법
- Nonpreemptive(비선점)
- 1, 4이 비선점이다
- cpu 사용을 안 빼기는 것이다.
- 1, 4이 비선점이다
- preemptive(선점)
- 2, 3이 선점이다
- CPU사용중에 우선순위가 높은 프로세스가 들어오면, 그 프로세스에게 사용을 넘겨준다.
- 2, 3이 선점이다
왜 이런일이 일어날까?
- 1, 4번은 새로 들어오는 것이 없다
- 2. 3번은 새로운 것들이 들어올 수 있기 떄문이다.
Dispatcher
Dispatcher 모듈
- switching context(현제의 프로세스 저장 다음에 오는 프로세스를 수행)
- switching to user mode
- jumping to the proper location in the user program to restart that program
Dispath latency: 디스페치하는 데 걸리는 시간
Scheduling Criteria
- CPU utilization(효율성): cpu를 얼마만큼 사용했는가
- Throughput(처리량): 일정한 시간 내에 몇 개의 프로세스를 처리했는가
- Turnaround time : 프로세스의 일이 다 끝날 때까지의 시간
- Waiting time: 기다리는 시간
- Response time: 서로 상홍작용 적인 상태에서 서로의 응답시간
First- Come, First-Served (FCFS) Scheduling
Process Burst Time
P1 24
P2 3
P3 3

FCFS
들어오는 순서대로 일을 처리하는 것이다
burst Time: 얼마만큼의 cpu를 사용하는 시간
평균 waiting time: 17

convoy effect: 짧은 거 뒤에 긴것을 연결한다.
Shortest-Job-First (SJF) Scheduling
SJF: 시간이 짧은 것부터 프로세스를 한다.
-> 그러면 가장 waiting time 평균이 가장 짧다.
하지만 이것은 실전에서는 아직 안된다.
왜냐하면, 어떤 프로세스가 짧고, 긴 것을 미리 알 수가 없다.
Determining Length of Next CPU Burst
정확히는 아니 지만, 예상하는 방법이다.
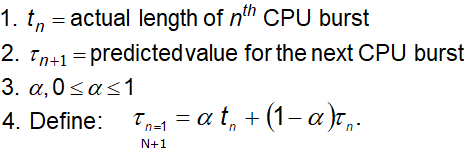
일반적으로, α는 1/2로 생각한다.

T(i) 예상 값
Cpu burst 실제 값
Example of Shortest-remaining-time-first
Process Arrival Time Burst Time
P1 0 8
P2 1 4
P3 2 9
P4 3 5

평균: 6.5msec Arrival Time: ready queue에 도착할 시간이다.
Priority(우선순위) Scheduling
A priority number -> 숫자가 생긴다
CPU는 가장 우선순위가 높은 프로세스 부터 실행된다.
- Preemptive(자기보다 우선순위가 높은 프로세스가 오면 선점을 당한다)
- Nonpreemptive(자기보다 우선순위가 높은 프로세스가 와도 선점당하지 않는다.)
Problem
Starvation(기아현상) -> 우선순위가 낮은 것은 무한대로 기다린다. -> 프로세스가 실행이 안된다
Solution
Aging(나이를 먹게 한다.) -> 프로세스의 우선순위를 올린다.
Example of Priority Scheduling

다 ready queue에 있다고 예상하는 것
이것은 비선점이다
Round Robin(RR)
각 프로세스마다 CPU를 사용할 수 있는 시간을 할당해 준다.
Ready queue에 있는 프로세스를 사용한다
일을 끝내지 못하면 ready queue에 돌아간다
제일 끝에 있는 프로세스는 (n-1)q의 시간이 걸린다.
q large -> FCFS(먼저 들어것아 먼저 실행)
q small -> q must be large with respect to context switch, otherwise overhead is too high(자주 프로세스들이 바뀐다. ovethead(처리 시간 or 메모리) 값이 크다.)
Example of RR with Time Quantum = 4
Process Burst Time
P1 24
P2 3 10
P3 3 12

P3가 끝나고 4마다 칸이 생기는 이유
-> 4마다 ready queue로 무조건 간다. 그래서 contect switch 발생 하지만 다른 프로세스가 없어서 p1이 실행된다.
Waiting Time 계산법
Waiting time = finish time – burst time – arrival time
예
P1 WT = 6
30(p1의 finish time) – 24(p1의 burst time) – 0(p1의arrival time) = 6
Multilevel Queue(ready queue)
foreground – RR
background – FCFS
기아현상이 일어난다. 하지만 aging방식은 사용하기 어렵다.
그래서 Time slice를 사용한다. Cpu를 사용하는 시간은 비율로 나눠준다.
Background는 20%를 준다.
Foreground는 80%를 준다.
Multilevel Queue Scheduling

각 ready queue 마다 우선순위가 있다. 위쪽의 우선순위가 높고, 아래쪽이 우선순위가 낮다
Example of Multilevel Feedback Queue

3개의 queue에 들어가는 것은 다 똑같다.
- 8이라는 시간에 끝나거는 나가고, 아닌 것은 2로 간다
- 16이라는 시간에 끝나거는 나가고, 아닌 것은 3으로 간다
- 여기서 모든 일을 끝낸다.
-> 이것도 SJF와 같은 원리이다.
시간이 짧은 것은 빨리 나가면 된다.
Thread Scheduling
유저 레벨에서도 스케줄링이 필요하다. 커널 또한 필요하다.
-> 라이브러리에서 정한다.(LWP에서 실행되도록 한다)
유저 레벨에서 하는 것은 PCS(Process Conntention Scope)로 알려져 있다.
시스템에서는 하는 것은 SCS(Systme-Contention Scope)이다.
Multiple-Processor(CPU같은) Scheduling
CPU가 여러개 있을 경우이다.
Symmetric multiprocessing (대칭) : CPU가 각 일을 똑같이 한다. 충돌할 수 있다. 두개의 일이 동시에 끝나면
Asymmetric multiprocessing (비대칭) : 하나의 CPU(master)가 다른 CPU에게 control한다. 충돌이 발생 X
Processor affinity(유사성)
soft affinity: 여러 processor 중 하나에서 run
hard affinity: 여러 processor에서 분산해서 run
Multiple-Processor Scheduling – Load Balancing
Load Balancing
CPU들이 적당히 일을 하기위해, 일의 balancing을 맞춘다
Push migration 일을 준다
Pull migration 일을 가져온다
이것을 하면서 balancing을 맞춘다.
Real-Time CPU Scheduling
Hard real-time systems
주어진 시간안에 모든 일이 끝내야 한다.
Soft real-time systems
조금 더 여유가 있다.
Algorithm Evaluation
어떤 알고리즘이 좋은가?
Deterministic modeling
- 제일 간단, 빨리 할 수 있다.
- 제일 비용이 적게 든다.
- 평균시간을 계산하는 것이다.
- ex) FCS, Non-preemprive SFJ, RR을 서로 비교하는 것이다.

1. w.T p1:0, p2:10 p3:39 p4 42 p5 49 평균: 28
2. w.T 평균: 13
3. w.T 평균: 23
w.T: finish time - burst time - arrival time
3번 p2wt: 64 – 29 = 32
Queueing Models
수식을 가지고 WT(Waiting Time)을 구한다.
Little’s Formula
n = λ x W
n: 평균 큐 길이
W: queue에서 기다리는 평균 값
Λ: 일정한 시간에 몇개에 프로세스가 도착하는 평균
Simulations(모의실험)
시간, 비용이 많이 든다. 하지만 정확도가 높다
프로그램을 가지고 시뮬레이션을 한다.
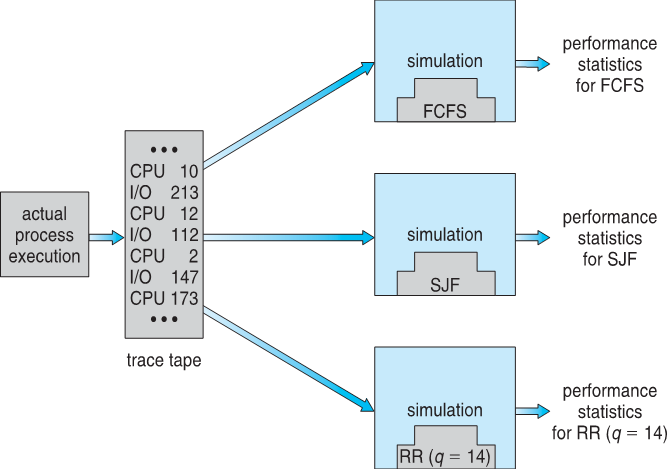
데이터(trace tape) -> 프로그램을 이용한다. -> FCFS, SJF, RR 결과가 나온다
시간,비용이 많이든다.
Implementation(실행)
제일 정확도가 높다. 이것은 실제로 프로세스를 실행시킨다.
but,
High cost, high risk
Environments vary
'os' 카테고리의 다른 글
Chapter 8: Deadlocks (0) 2020.10.26 Chapter 6: Synchronization Tools (0) 2020.10.16 Chapter 2: Operating-System Structures (0) 2020.10.11 Chapter 1: Introduction (0) 2020.09.18 Chapter 3: Processes (0) 2020.09.16