-
머신러닝 만들기 - K최근접 이웃회귀기계학습 2021. 9. 24. 16:19
농어의 무게를 예측
농어의 길이를 보고 무게를 예측하는 것을 만드는 것이다.
농어의 길이를 준비한다.
import matplotlib.pyplot as plt plt.scatter(perch_length, perch_weight) plt.xlabel('length') plt.ylabel('weight') plt.show()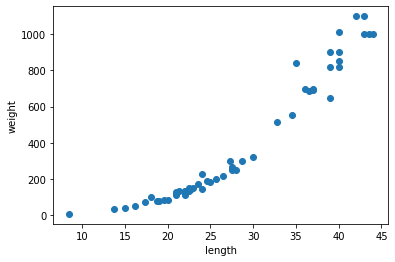
훈련세트를 준비한다.
train_test_split를 쓴다.
from sklearn.model_selection import train_test_split train_input, test_input, train_target, test_target = train_test_split( perch_length, perch_weight, random_state=42) train_input = train_input.reshape(-1, 1) test_input = test_input.reshape(-1, 1)
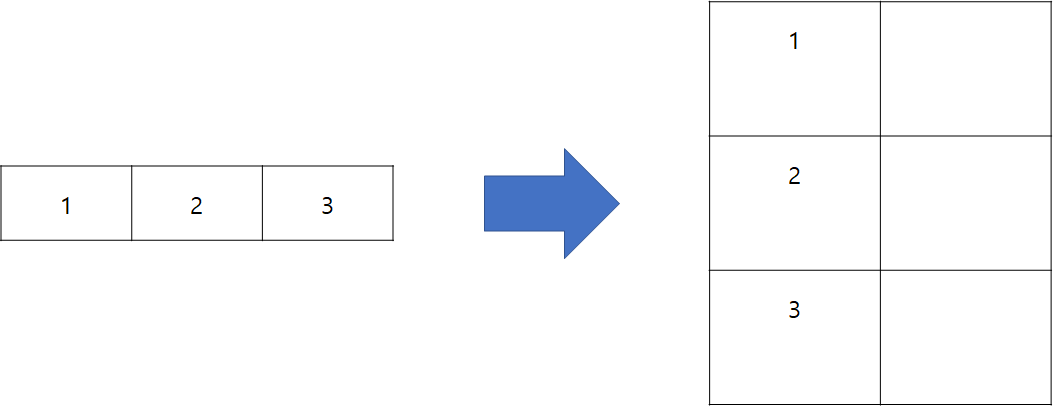
마지막, reshape(-1, 1)을 하면, 1차원 배열이 였던 것이, 2차원 배열로 변한다.
결정계수를 구한다.
추정한 선형 모형이 주어진 자료에 적합한 정도를 재는 척도이다.
식은

이다.
의미하는 것은 1에 가까운 값을 가지면 이 머신러닝이 유용성이 아주 높다는 것을 의미한다.
이웃의 개수를 줄이기

과대 접합이라고 판단할 수 있다. 과대접합을 피하기 위해서 이웃의 개수를 줄인다.



특성 공학과 규제 (여러가지 회귀)
특징이 여러게 있을 경우
다항 특성 만들다.
df = pd.read_csv('https://bit.ly/perch_csv') perch_full = df.to_numpy() [[ 8.4 2.11 1.41] [13.7 3.53 2. ] [15. 3.82 2.43] [16.2 4.59 2.63] ... # 변환기 from sklearn.preprocessing import PolynomialFeatures # degree=2 # poly = PolynomialFeatures() poly.fit([[2,3]]) # 1(bias), 2, 3, 2**2, 2*3, 3**2 # transform 값을 변화시켜주는 메소드 print(poly.transform([[2,3]]))규제(Regularization)
- 머신러닝 모델이 훈련 세트를 너무 과도하게 학습하지 못하도록 훼방하는 것(과대적합)
- 계수(또는 기울기)의 크기를 작게 만드는 일이다.

너무 과도하게 특성이 많아지면, 테스트의 에러가 많아진다.
B3, B4가 1이 되기만 해도, 왼쪽 값이 엄청난 영향을 주게 된다.
그래서, 최대한 0으로 만들어주는 것이 중요하다.

규제의 개념
𝜆 : typer parameter, 베타 값을 컨트롤 하는 용도이다.
규제 방법
L2 norm : B에 제곱해준다
L1 norm : B에 절대값을 넣는다왼쪽은 훈련 값, 오른쪽은 일반값
b1 : ax + b
p개의 특징
b1,b2,b3 ....bp
모델 P라고 한다
릿지(Ridge) 회귀


RSS(데이터와 추정 모델 사이의 불일치 평가=전차 제곱합)
- L2norm을 의미한다.
- RSS는 그림에서 타원형(L)을 의미한다.
- 이 제약조건에 타원형 원이 가까워 지면, 더 정확한 예측이 나온다.
- 람다값을 적절하게 찾아줘야 한다.
- 자주 쓰이는 방법이다.
라쏘(Lasso) 회귀


- L1norm을 의미한다.
- 릿지 회귀에 비해 몇몇 유의미하지 않은 변수들에 대해서 0에 가깝게 추정한다.
- 모델을 단순하게 만들어 주어서 잘 쓰지는 않는다.
'기계학습' 카테고리의 다른 글
분류 알고리즘 (0) 2021.10.01 머신 러닝 만들기 - 선형 회귀 (0) 2021.09.24 회귀 (0) 2021.09.24 머신 러닝 만들기 - 데이터 전처리 (0) 2021.09.17 데이터 전처리 (0) 2021.09.17